安装启动 windows
启动zookeeper
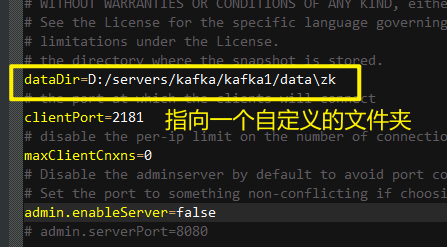
修改配置文件
cd config/zookeeper.properties
启动
cd bin\windows
zookeeper-server-start.bat D:\servers\kafka\kafka1\config\zookeeper.properties
创建启动脚本
创建一个 zk.cmd文件
写入启动命令
call D:\servers\kafka\kafka1\bin\windows\zookeeper-server-start.bat D:\servers\kafka\kafka1\config\zookeeper.properties
启动 kafka
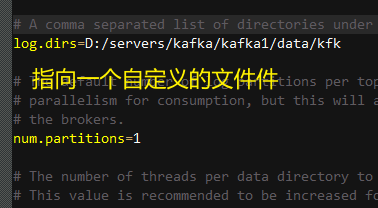
修改配置文件
修改文件D:\servers\kafka\kafka1\config\server.properties
创建启动文件
创建kfk.cmd文件 写入
call D:\servers\kafka\kafka1\bin\windows\kafka-server-start.bat D:\servers\kafka\kafka1\config\server.properties
双击则可启动
代码链接kafka
pom
<dependency>
<groupId>org.springframework.kafka</groupId>
<artifactId>spring-kafka</artifactId>
<version>3.1.6</version>
</dependency>
生产者
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerConfig;
import org.apache.kafka.clients.producer.ProducerRecord;
import org.apache.kafka.common.serialization.StringSerializer;
import java.util.HashMap;
import java.util.Map;
public class KafkaProduceTest {
public static void main(String[] args) {
try {
// 配置文件
Map<String,Object> configMap = new HashMap<>();
configMap.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,"localhost:9092");
configMap.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
configMap.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,StringSerializer.class.getName());
// 创建kafaka链接
KafkaProducer<String,String> producer = new KafkaProducer<>(configMap);
// 创建生产者对象
ProducerRecord<String,String> record = new ProducerRecord<>("test", "key","value");
// 发送消息
producer.send(record);
// 关闭
producer.close();
}catch (Exception e){
e.printStackTrace();
}
}
}
消费者
import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import org.apache.kafka.common.serialization.StringDeserializer;
import java.util.Collections;
import java.util.HashMap;
import java.util.Map;
public class KafkaConsumerTest {
public static void main(String[] args) {
Map<String, Object> consumerConfig = new HashMap<>();
consumerConfig.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG,"localhost:9092");
consumerConfig.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
consumerConfig.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
// 这个应该是设置 消费者组
consumerConfig.put(ConsumerConfig.GROUP_ID_CONFIG, "xiong");
// 创建消费者对象
KafkaConsumer<String,String> consumer = new KafkaConsumer(consumerConfig);
// 订阅主题
consumer.subscribe(Collections.singletonList("test"));
// 获取数据
while (true){
ConsumerRecords<String, String> datas = consumer.poll(100);
for (ConsumerRecord<String, String> data : datas) {
System.out.println("------");
System.out.println(data);
}
}
}
}
工具连接
kafkaTool
下载地址
https://www.kafkatool.com/download.html
配置
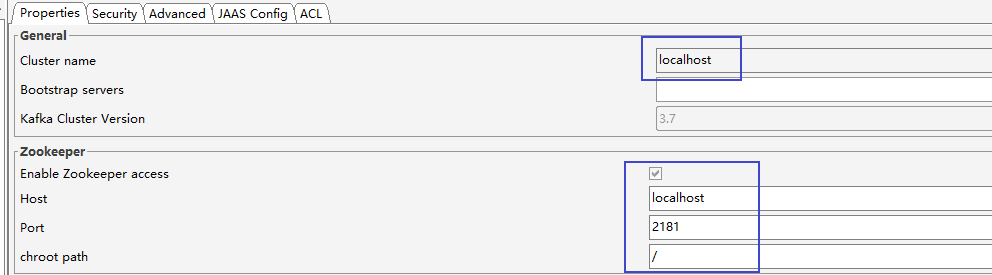
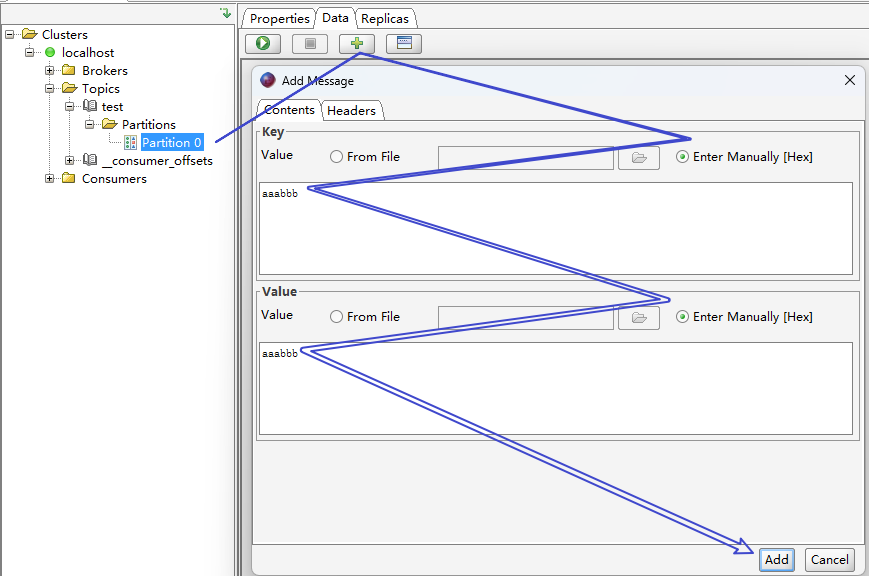
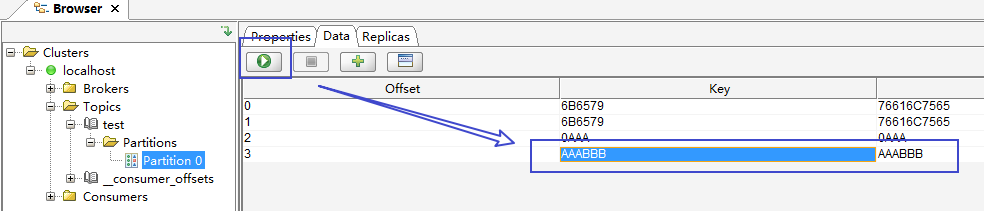
新增一个消息
面试题
如何保证数据的可靠性
生产者设置ack
- ack=1:数据发送成功后,返回ack,不能保证数据已经保存在数据库中。
- ack=2:数据保存到leader中会返回ack,不能保证数据已经保存备份。
- ack=-1(all):数据在leader和备份中都保存好以后,返回ack。
生产者进行发送重试,
- 乱序:因为kafka在发送消息的时候,会存在一个缓冲区,如此生产者发送消息的的时候,是成批进行发送的。然后有可能一批中,有几个发送成功了,有几个没有发送成功的,如果重试没有发送成功的消息,就会和第一次的数据产生乱序的问题。
- 重复:如果说生产者发送了数据,并且kafka服务器已经保存了数据,但是kafka在返回ack的时候,出现异常,则生产者以为没有保存成功,会进行重复发送,此时数据会出现重复
生产者幂等性配置:可以解决重复和乱序的问题。
- 要求一:ack = -1
- 要求二:开启重试机制
- 要求三:在途请求缓冲区数量不能大于5(默认就是5)
- 原理:
- 1、在缓冲区的每一个生产者和每一个批次都设置一个标识(生产者id),
- 2、给数据设置顺序号,
开启事务
- 可以进行配置,然后再编码的时候,设置开启事务、提交事务、中止事务。
消费者重复消费
偏移量,每次消费都会带上偏移量,所以一般不会出现重复消费的问题,
但是偏移量默认每5秒保存一次,所以如果消费者发生宕机,可能会重复消费到最后五秒的数据。
- 解决方案一:缩小保存偏移量的时间,只能解决一部分问题、性能下降。
- 解决方案二:手动保存偏移量,在获取数据后,主动提交保存偏移量的请求,但是还是不能完全解决问题,因为可能会出现网络问题。
- 同步提交:会保证数据的完整性,但是如果提交不成功,会出现阻塞
- 异步提交:可能会出现保存不成功的情况,出现重复消费数据
- 解决方案三:通过业务判断是否重复消费。
- 解决方案四:
监控工具
kafka-Eagle
安装:略
无zookeeper模式
Kraft模式
安装:略

